En un post anterior comentaba que submuestrear si es pecado. En este post vengo a contar algo así como un contraejemplo a mi mismo. O más bien, podríamos decir aquello de “dónde no hay no se puede sacar”, ¿ o si?
Para ver esto usaré un dataset muy conocido que está disponible en Kaggle, el de credit card. El sábado echando unas cerves con mi amigo Francisco me contaba que a él le salía bien sin submuestrear incluso haciendo una regresión logística, pero a mi no. Veamos.
Credit card
El típico ejemplo de creditcard de kagle.
Show the code
# pruebo esto de la funcińo use nueva en r base.use(package ="pROC", c("roc", "auc"))use(package ="yardstick", c("mn_log_loss_vec"))creditcard<-data.table::fread(here::here("data/creditcard.csv"))|>as.data.frame()creditcard$Class<-as.factor(creditcard$Class)table(creditcard$Class)#> #> 0 1 #> 284315 492skimr::skim(creditcard)
Comparando los tres glms con unas pocas variables, submuestrear parece ser mejor
Modelo normal sin submuestrear
No uso la variable Time, ni me caliento la cabez en buscar interacciones (por el momento)
Show the code
f1<-as.formula("Class ~ V1 + V2 + V3 + V4 + V5 +V6 + V7 + V8 + V9 + V10 + V11 + V12 +V13 +V14 + Amount")glm1<-glm(f1, family =binomial, data =train)(roc_glm<-roc(test$Class, predict(glm1, newdata =test, type ="response")))#> #> Call:#> roc.default(response = test$Class, predictor = predict(glm1, newdata = test, type = "response"))#> #> Data: predict(glm1, newdata = test, type = "response") in 144564 controls (test$Class 0) < 243 cases (test$Class 1).#> Area under the curve: 0.5(logloss_glm<-mn_log_loss_vec(as.factor(test$Class), predict(glm1, newdata =test, type ="response"), event_level ="second"))#> [1] 0.0604847# logloss(ytrue, predict(glm1, newdata = test, type = "response"))
Modelo glm submuestreado
Vamos a submuestrear la clase 0, pero no demasiado, nos quedamos con 3000
Show the code
samples_0<-train[sample(rownames(train[train$Class=="0",]), 3000),]table(samples_0$Class)#> #> 0 1 #> 3000 0train_subsample<-rbind(samples_0, train[train$Class=="1", ])table(train_subsample$Class)#> #> 0 1 #> 3000 249glm2<-glm(f1, family =binomial, data =train_subsample)(roc_glm_submuestreo<-pROC::roc(test$Class, predict(glm2, newdata =test, type ="response")))#> #> Call:#> roc.default(response = test$Class, predictor = predict(glm2, newdata = test, type = "response"))#> #> Data: predict(glm2, newdata = test, type = "response") in 144564 controls (test$Class 0) < 243 cases (test$Class 1).#> Area under the curve: 0.5546(logloss_glm_submuestreo<-mn_log_loss_vec(as.factor(test$Class), predict(glm2, newdata =test, type ="response"), event_level ="second"))#> [1] 0.2523929
Y en este caso , submuestrear parece ser mejor.
Modelo glm con pesos
Show the code
# Pesos inversamente proporcionales al tamaño de la clasepesos<-ifelse(train$Class=="1", sum(train$Class=="0")/sum(train$Class=="1"), 1)# Modelo con pesosglm_pesos<-glm(f1, family =binomial, data =train, weights =pesos)(roc_glm_pesos<-pROC::roc(test$Class, predict(glm_pesos, newdata =test, type ="response")))#> #> Call:#> roc.default(response = test$Class, predictor = predict(glm_pesos, newdata = test, type = "response"))#> #> Data: predict(glm_pesos, newdata = test, type = "response") in 144564 controls (test$Class 0) < 243 cases (test$Class 1).#> Area under the curve: 0.5(logloss_glm_pesos<-mn_log_loss_vec(as.factor(test$Class), predict(glm_pesos, newdata =test, type ="response"), event_level ="second"))#> [1] 35.98317
Y vemos que una regresión logística al uso no es suficiente para pillar hacer un modelo, en este caso submuestrear no es pecado, y no se ha arreglado usando pesos.
¿Pero y si usamos cosas de esas modernas, como los boosting?
# Calcular el ratio de clasesratio<-sum(train$Class=="0")/sum(train$Class=="1")# Entrenamiento con pesosxgb3<-xgboost(data =dtrain, nrounds =100, objective ="binary:logistic", scale_pos_weight =ratio, verbose =0)(roc_xgb_pesox<-pROC::roc(test$Class, predict(xgb3, dtest)))#> #> Call:#> roc.default(response = test$Class, predictor = predict(xgb3, dtest))#> #> Data: predict(xgb3, dtest) in 144564 controls (test$Class 0) < 243 cases (test$Class 1).#> Area under the curve: 0.9642(logloss_xgb_pesos<-mn_log_loss_vec(as.factor(test$Class), predict(xgb3, newdata =dtest), event_level ="second"))#> [1] 0.003572369
Pues los xgboost funcionan bien sea como sea.
Bayesiano
Y si hacemos una regresión logística bayesiana, pero poniendo como prior del intercept lo observado en los datos
Show the code
# ponemos como prior el logit de la prevalenciaºprop.table(table(train$Class))#> #> 0 1 #> 0.998221429 0.001778571qlogis(0.0017)# ≈ -6.38#> [1] -6.375426options(brms.backend ="cmdstanr")library(brms)f_hs<-bf(Class~V1+V2+V3+V4+V5+V6+V7+V8+V9+V10+V11+V12+V13+V14+Amount)prior_hs<-c(set_prior("horseshoe(2)", class ="b"), # regularización para coeficientesset_prior("normal(-6.4, 2)", class ="Intercept")# prior centrado en la prevalencia)
El modelo full bayesian tarda bastante en Stan (tengo que poner el código en numpyro). ASí que cuando terminó de ajustarse lo guardé en un objeto serializado que luego llamaré
Show the code
modelo_brm<-brm(f_hs, data =train, family =bernoulli(link ="logit"), prior =prior_hs, algorithm ="sampling", file ="modelo_brm_1", file_refit ="on_change", chains =6, iter =4000, cores =6, backend ="cmdstanr")
Puedo hacer inferencia variacional para ver por dónde van los tiros
Show the code
modelo_brm_vi<-brm(f_hs, data =train, family =bernoulli(link ="logit"), prior =prior_hs, algorithm ="meanfield", chains =6, iter =4000, cores =6, backend ="cmdstanr")#> ------------------------------------------------------------ #> EXPERIMENTAL ALGORITHM: #> This procedure has not been thoroughly tested and may be unstable #> or buggy. The interface is subject to change. #> ------------------------------------------------------------ #> Gradient evaluation took 0.005593 seconds #> 1000 transitions using 10 leapfrog steps per transition would take 55.93 seconds. #> Adjust your expectations accordingly! #> Begin eta adaptation. #> Iteration: 1 / 250 [ 0%] (Adaptation) #> Iteration: 50 / 250 [ 20%] (Adaptation) #> Iteration: 100 / 250 [ 40%] (Adaptation) #> Iteration: 150 / 250 [ 60%] (Adaptation) #> Iteration: 200 / 250 [ 80%] (Adaptation) #> Success! Found best value [eta = 1] earlier than expected. #> Begin stochastic gradient ascent. #> iter ELBO delta_ELBO_mean delta_ELBO_med notes #> 100 -1145.629 1.000 1.000 #> 200 -777.796 0.736 1.000 #> 300 -711.459 0.522 0.473 #> 400 -698.357 0.396 0.473 #> 500 -692.432 0.148 0.093 #> 600 -697.675 0.032 0.019 #> 700 -689.003 0.012 0.013 #> 800 -698.835 0.011 0.013 #> 900 -683.979 0.014 0.014 #> 1000 -708.684 0.021 0.022 #> 1100 -687.713 0.025 0.030 #> 1200 -685.163 0.023 0.030 #> 1300 -684.128 0.018 0.030 #> 1400 -689.093 0.011 0.007 MEDIAN ELBO CONVERGED #> Drawing a sample of size 1000 from the approximate posterior... #> COMPLETED. #> Finished in 15.9 seconds.summary(modelo_brm_vi)#> Family: bernoulli #> Links: mu = logit #> Formula: Class ~ V1 + V2 + V3 + V4 + V5 + V6 + V7 + V8 + V9 + V10 + V11 + V12 + V13 + V14 + Amount #> Data: train (Number of observations: 140000) #> Draws: 1 chains, each with iter = 1000; warmup = 0; thin = 1;#> total post-warmup draws = 1000#> #> Regression Coefficients:#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS#> Intercept -8.09 0.11 -8.28 -7.87 1.00 1036 1069#> V1 -0.00 0.01 -0.03 0.03 1.00 911 840#> V2 -0.00 0.02 -0.04 0.03 1.00 1013 880#> V3 0.01 0.02 -0.01 0.05 1.00 908 847#> V4 0.48 0.05 0.39 0.57 1.00 651 883#> V5 0.00 0.02 -0.03 0.04 1.00 1037 927#> V6 -0.01 0.04 -0.10 0.06 1.00 954 941#> V7 -0.02 0.03 -0.08 0.00 1.00 1018 982#> V8 -0.14 0.04 -0.22 -0.08 1.00 862 980#> V9 -0.01 0.04 -0.10 0.05 1.00 959 819#> V10 -0.43 0.06 -0.55 -0.32 1.00 964 881#> V11 0.00 0.03 -0.03 0.06 1.00 696 749#> V12 -0.32 0.07 -0.45 -0.20 1.00 906 936#> V13 -0.01 0.06 -0.10 0.03 1.00 902 906#> V14 -0.62 0.05 -0.71 -0.53 1.00 1036 1026#> Amount -0.00 0.00 -0.00 0.00 1.00 1064 854#> #> Draws were sampled using variational(meanfield).
Y como tenía entrenado y guardado el modelo full bayesian, lo puedo comparar
Y para calcular el roc auc hago la predicción de la media condicianada para cada observación.
Show the code
probs_brm<-posterior_epred(modelo_brm_vi, newdata =test, ndraws =1000)|>colMeans()y_true<-test$Class(roc_brm<-roc(y_true, probs_brm))#> #> Call:#> roc.default(response = y_true, predictor = probs_brm)#> #> Data: probs_brm in 144564 controls (y_true 0) < 243 cases (y_true 1).#> Area under the curve: 0.9744
Y el modelo bayesiano sin submuestrear con prior sobre el intercept funciona igual de bien que los xgboost, y es más interpretable.
Una cosa que nos permite el modelo bayesiano es obtener la incertidumbre de las predicciones. No la predicción de la media condicionada, sino la de cada observación, en esa predicción se le añade la incertidumbre debida a la distribución de los datos.
No es lo correcto para evaluar el modelo via auc_roc, pero podemos ver que sale
Show the code
probs_brm_noise<-predict(modelo_brm, newdata =test, type ="response",ndraws =1000)[, "Estimate"](roc_brm_noise<-roc(y_true, probs_brm_noise))#> #> Call:#> roc.default(response = y_true, predictor = probs_brm_noise)#> #> Data: probs_brm_noise in 144564 controls (y_true 0) < 243 cases (y_true 1).#> Area under the curve: 0.9384
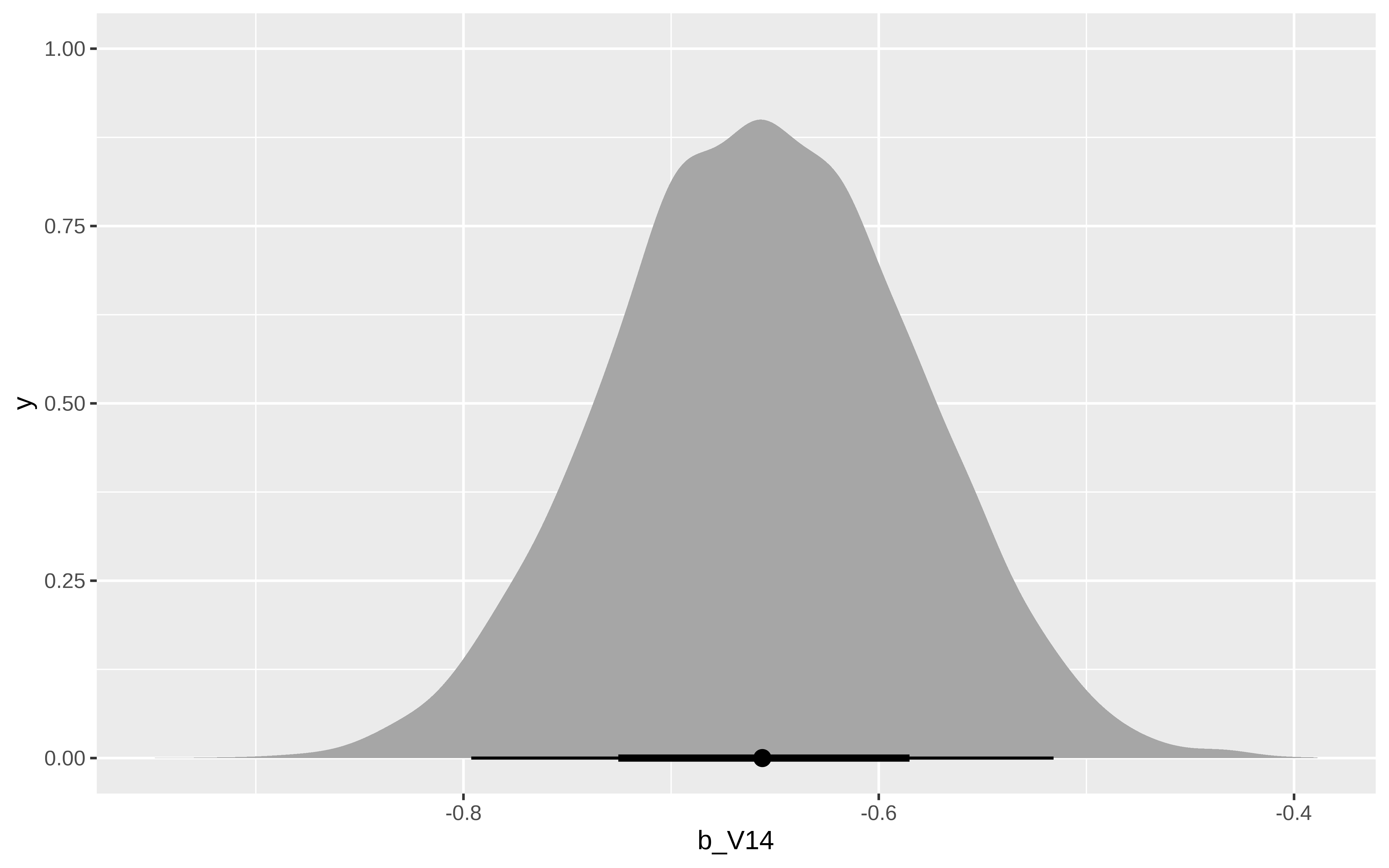
Podemos ordenar las variables por su coeficiente, por ejemplo
A veces que esté muy desbalanceado el conjunto de datos hace que modelos sencillos como una regresión logística no funcione del todo bien, (hay mucho ruido en los 0’s). Otros modelos más complejos parecen funcionar bien, tanto sobre los datos originales, submuestreados o usando pesos. Pero dando un paso atrás y pensando en restringir el intercept de un modelo usando la prevalencia podemos ajustar un modelo bayesiano simple e interpretable y que funciona casi igual que esos modelos más complejos, y utilizando toda la información disponible. Curioso cuánto menos.
Source Code
---title: Submuestrear (a veces) no es pecado.Ejemplodate: '2025-5-11'categories: - estadística - muestreo - "2025"description: ''execute: message: false warning: false echo: true output: trueformat: html: toc: true fig-height: 5 fig-dpi: 300 fig-width: 8 fig-align: center code-fold: show code-link: true code-summary: "Show the code" code-tools: true knitr: opts_chunk: out.width: 80% fig.showtext: TRUE collapse: true comment: "#>"image: "v14.png"---::: callout-note## Listening<iframe style="border-radius:12px" src="https://open.spotify.com/embed/track/36WqxoYjWue4p2jPBocu6y?utm_source=generator" width="100%" height="352" frameBorder="0" allowfullscreen="" allow="autoplay; clipboard-write; encrypted-media; fullscreen; picture-in-picture" loading="lazy"></iframe>:::En un [post anterior](2025/03/submuestrear.html) comentaba que submuestrear si es pecado. En este post vengo a contar algo así como un contraejemplo a mi mismo. O más bien, podríamos decir aquello de "dónde no hay no se puede sacar", ¿ o si? Para ver esto usaré un dataset muy conocido que está disponible en Kaggle, el de credit card. El sábado echando unas cerves con mi amigo Francisco me contaba que a él le salía bien sin submuestrearincluso haciendo una regresión logística, pero a mi no. Veamos. ## Credit cardEl típico ejemplo de creditcard de kagle. ```{r}# pruebo esto de la funcińo use nueva en r base.use(package ="pROC", c("roc", "auc"))use(package ="yardstick", c("mn_log_loss_vec"))creditcard <- data.table::fread(here::here("data/creditcard.csv")) |>as.data.frame()creditcard$Class <-as.factor(creditcard$Class)table(creditcard$Class)skimr::skim(creditcard)```El dataset está muy desbalanceado. ```{r}id_train <-sample(1:nrow(creditcard), 140000)id_test <-setdiff(1:nrow(creditcard), id_train)train <- creditcard[id_train, ]test <- creditcard[id_test, ](t1 <-table(train$Class))(t2 <-table(test$Class))prop.table(t1)prop.table(t2)```## Modelos glm normal, con submuestreo y con pesos Comparando los tres glms con unas pocas variables, submuestrear parece ser mejor### Modelo normal sin submuestrearNo uso la variable Time, ni me caliento la cabez en buscar interacciones (por el momento)```{r}f1 <-as.formula("Class ~ V1 + V2 + V3 + V4 + V5 +V6 + V7 + V8 + V9 + V10 + V11 + V12 +V13 +V14 + Amount")glm1 <-glm(f1, family = binomial, data = train)(roc_glm <-roc(test$Class, predict(glm1, newdata = test, type ="response")))(logloss_glm <-mn_log_loss_vec(as.factor(test$Class), predict(glm1, newdata = test, type ="response"), event_level ="second"))# logloss(ytrue, predict(glm1, newdata = test, type = "response"))```### Modelo glm submuestreadoVamos a submuestrear la clase 0, pero no demasiado, nos quedamos con 3000```{r}samples_0 <- train[sample(rownames(train[train$Class =="0",]), 3000),]table(samples_0$Class)train_subsample <-rbind(samples_0, train[train$Class=="1", ])table(train_subsample$Class)glm2 <-glm(f1, family = binomial, data = train_subsample)(roc_glm_submuestreo <- pROC::roc(test$Class, predict(glm2, newdata = test, type ="response")))(logloss_glm_submuestreo <-mn_log_loss_vec(as.factor(test$Class), predict(glm2, newdata = test, type ="response"), event_level ="second"))```Y en este caso , submuestrear parece ser mejor. ### Modelo glm con pesos```{r}# Pesos inversamente proporcionales al tamaño de la clasepesos <-ifelse(train$Class =="1", sum(train$Class =="0")/sum(train$Class =="1"), 1)# Modelo con pesosglm_pesos <-glm(f1, family = binomial, data = train, weights = pesos)(roc_glm_pesos <- pROC::roc(test$Class, predict(glm_pesos, newdata = test, type ="response")))(logloss_glm_pesos<-mn_log_loss_vec(as.factor(test$Class), predict(glm_pesos, newdata = test, type ="response"), event_level ="second"))```Y vemos que una regresión logística al uso no es suficiente para pillar hacer un modelo, en este caso submuestrear no es pecado, y no se ha arreglado usando pesos. ¿Pero y si usamos cosas de esas modernas, como los boosting? ## Al BoostingA ver qué pasa### Boosting tal cual```{r}library(xgboost)vars <-c("V1", "V2", "V3", "V4", "V5", "V6", "V7", "V8", "V9", "V10", "V11", "Amount")# Preparamos las matricesdtrain <-xgb.DMatrix(data =as.matrix(train[, vars]), label =as.numeric(as.character(train$Class)))dtest <-xgb.DMatrix(data =as.matrix(test[, vars]), label =as.numeric(as.character(test$Class)))# Entrenamosxgb1 <-xgboost(data = dtrain, nrounds =100, objective ="binary:logistic", verbose =0)# AUC(roc_xg_boost <- pROC::roc(test$Class, predict(xgb1, dtest)))(logloss_xgb<-mn_log_loss_vec(as.factor(test$Class), predict(xgb1, newdata = dtest), event_level ="second"))```Vaya, pues el boosting lo hace muy bien, al fin y al cabo son árboles encadenados, y pilla bien las interacciones### Boosting submuestreando```{r}samples_0 <- train[sample(rownames(train[train$Class =="0",]), sum(train$Class =="1")), ]train_sub <-rbind(samples_0, train[train$Class =="1", ])dtrain_sub <-xgb.DMatrix(data =as.matrix(train_sub[, vars]), label =as.numeric(as.character(train_sub$Class)))xgb2 <-xgboost(data = dtrain_sub, nrounds =100, objective ="binary:logistic", verbose =0)# AUC(roc_xgb_submues <- pROC::roc(test$Class, predict(xgb2, dtest)))(logloss_xgb_submues<-mn_log_loss_vec(as.factor(test$Class), predict(xgb2, newdata = dtest), event_level ="second"))```### Boosting con pesos```{r}# Calcular el ratio de clasesratio <-sum(train$Class =="0") /sum(train$Class =="1")# Entrenamiento con pesosxgb3 <-xgboost(data = dtrain, nrounds =100, objective ="binary:logistic",scale_pos_weight = ratio, verbose =0)(roc_xgb_pesox <- pROC::roc(test$Class, predict(xgb3, dtest)))(logloss_xgb_pesos <-mn_log_loss_vec(as.factor(test$Class), predict(xgb3, newdata = dtest), event_level ="second"))```Pues los xgboost funcionan bien sea como sea.## BayesianoY si hacemos una regresión logística bayesiana, pero poniendo como prior del intercept lo observado en los datos```{r}# ponemos como prior el logit de la prevalenciaºprop.table(table(train$Class))qlogis(0.0017) # ≈ -6.38options(brms.backend ="cmdstanr")library(brms)f_hs <-bf(Class ~ V1 + V2 + V3 + V4 + V5 + V6 + V7 + V8 + V9 + V10 + V11 +V12 + V13 + V14 + Amount)prior_hs <-c(set_prior("horseshoe(2)", class ="b"), # regularización para coeficientesset_prior("normal(-6.4, 2)", class ="Intercept") # prior centrado en la prevalencia)```El modelo full bayesian tarda bastante en Stan (tengo que poner el código en numpyro). ASí que cuando terminó de ajustarse lo guardé en un objeto serializado que luego llamaré```{r}#| eval: falsemodelo_brm <-brm( f_hs,data = train,family =bernoulli(link ="logit"),prior = prior_hs,algorithm ="sampling",file ="modelo_brm_1",file_refit ="on_change",chains =6, iter =4000, cores =6,backend ="cmdstanr")```Puedo hacer inferencia variacional para ver por dónde van los tiros```{r}modelo_brm_vi <-brm( f_hs,data = train,family =bernoulli(link ="logit"),prior = prior_hs,algorithm ="meanfield",chains =6, iter =4000, cores =6, backend ="cmdstanr")summary(modelo_brm_vi)```Y como tenía entrenado y guardado el modelo full bayesian, lo puedo comparar```{r}modelo_brm <-readRDS(here::here("modelo_brm_1.rds"))summary(modelo_brm)```Y para calcular el roc auc hago la predicción de la media condicianada para cada observación. ```{r}probs_brm <-posterior_epred(modelo_brm_vi, newdata = test, ndraws =1000) |>colMeans()y_true <- test$Class(roc_brm <-roc(y_true, probs_brm))```Y el modelo bayesiano sin submuestrear con prior sobre el intercept funciona igual de bien que los xgboost, y es más interpretable.Una cosa que nos permite el modelo bayesiano es obtener la incertidumbre de las predicciones. No la predicción de la media condicionada, sino la de cada observación, en esa predicción se le añade la incertidumbre debida a la distribución de los datos. No es lo correcto para evaluar el modelo via auc_roc, pero podemos ver que sale```{r}probs_brm_noise <-predict(modelo_brm, newdata = test, type ="response",ndraws =1000)[, "Estimate"](roc_brm_noise <-roc(y_true, probs_brm_noise))```Podemos ordenar las variables por su coeficiente, por ejemplo ```{r}library(tidyverse)coefs <-as_draws_df(modelo_brm)# Extraemos solo las betas (coeficientes, no el intercepto ni parámetros auxiliares)betas <- coefs %>%select(starts_with("b_")) %>%pivot_longer(cols =everything(), names_to ="term", values_to ="value")# Calculamos media y percentiles(summary_betas <- betas %>%group_by(term) %>%summarise(mean =mean(value),q025 =quantile(value, 0.025),q975 =quantile(value, 0.975) ) %>%arrange(desc(abs(mean)))) # ordenamos por magnitud de efectojjmodelo_brm |> tidybayes::spread_draws(b_V14) |>ggplot(aes( x = b_V14)) + tidybayes::stat_halfeye()```## CodaA veces que esté muy desbalanceado el conjunto de datos hace que modelos sencillos como una regresión logística no funcione del todo bien, (hay mucho ruido en los 0's). Otros modelos más complejos parecen funcionar bien, tanto sobre los datos originales, submuestreados o usando pesos. Pero dando un paso atrás y pensando en restringir el intercept de un modelo usando la prevalencia podemos ajustar un modelo bayesianosimple e interpretable y que funciona casi igual que esos modelos más complejos, y utilizando toda la información disponible. Curioso cuánto menos.